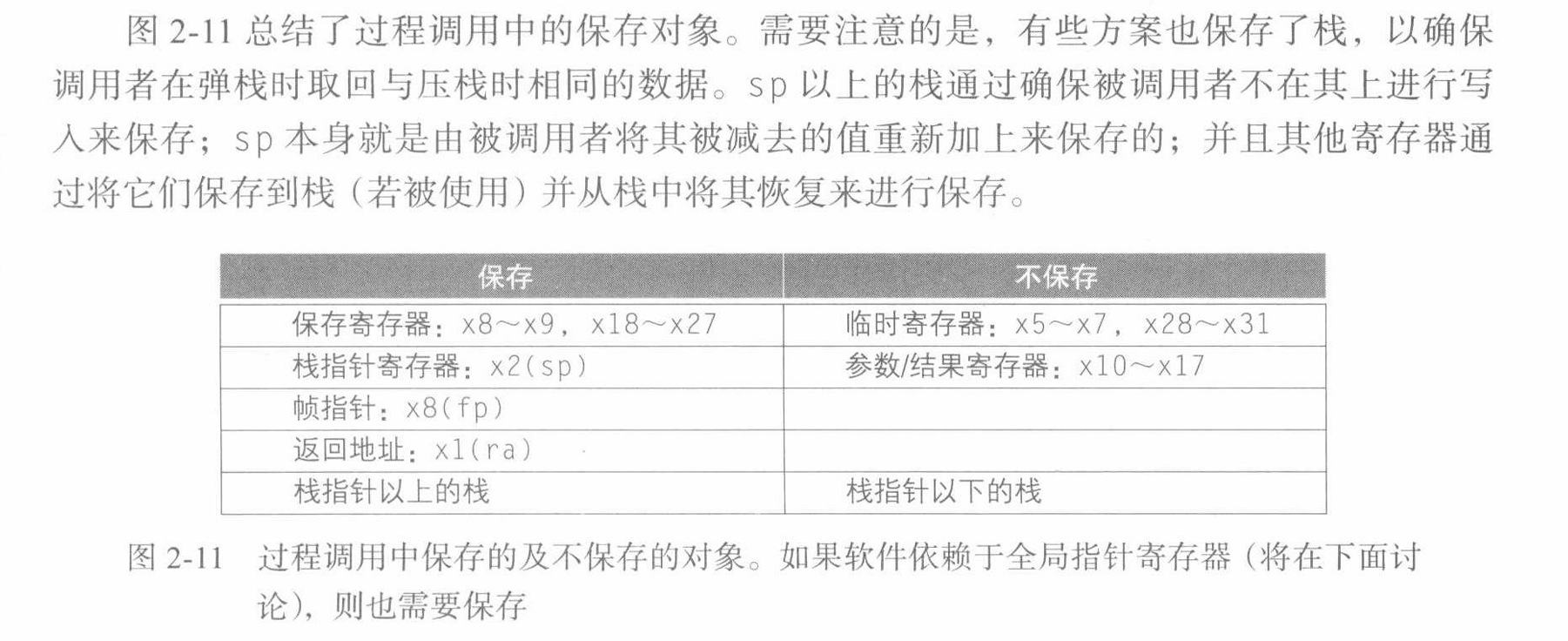
武汉大学《计算机组成与设计》课程的课程笔记,使用 David Patterson 的教材书,并针对书中的一些不清晰的地方做了详尽的注解。
The notes of the course Computer Composition and Design in Wuhan University. Use the textbook of David Patterson, and make detailed annotations for some unclear points in the book.
Introduction
A General Structure
摩尔定律(Moore’s law):芯片上的晶体管集成度每 18 个月翻一番。
计算机体系结构中的 8 个伟大思想:
- 面向摩尔定律的设计:由于快速的迭代速度,架构师必须预测其设计完成时的工艺水平。
- 使用抽象简化设计:区分不同的设计层次,隐藏底层细节以提供给高层一个更简单的模型。
- 加速经常性事件:相比优化罕见情形,很多时候这样更简单且更好提升性能。
- 通过并行提高性能。
- 通过流水线提高性能。
- 通过预测提高性能:在某些情况下,假设从预测错误中恢复的代价并不高,且预测相对准确,则平均来说进行预测并开始工作可能会比等到明确结果后再执行更快。
- 存储层次:给程序员一种主存和存储层次顶层一样快的速度、与底层一样大的容量和价格的错觉。
- 通过冗余提高可靠性:我们需要引入冗余组件来让系统发生故障时可以代替失效组件并帮助检测故障。
- 系统软件中最重要的是操作系统和编译器。操作系统(operating system)是用户程序和硬件之间的接口,为用户提供服务和监控功能;编译器(compiler)负责把高级语言编写的程序翻译成硬件能执行的指令。高级语言可以让程序员用更自然的语言来思考,提高其独立性,并提高了程序相对于计算机的独立性(不同计算机的编译器和汇编器可能存在区别)。
- 汇编器(assembler)可以将助记符形式的指令自动翻译成对应的二进制。助记符形式的指令成为汇编语言(assembly language),机器可以理解的二进制语言是机器语言(machine language)。

Hardware
计算机的两个关键部件是输入设备(input device)和输出设备(output device)。输入为计算机提供数据,输出将结果送给用户。无线网络等设备既是输入又是输出设备。
集成电路也叫芯片,是一种继承了大量晶体管的设备。
- 芯片中大多含有处理器,是计算机中最活跃的部分,严格按照程序中的指令运行,完成数据相加、数据测试、按结果发出控制信号使 I/O 设备做出动作等操作。有时候,人们把处理器称为中央处理单元( central processor unit),即 CPU。处理器从逻辑上包括两个主要部件:数据通路和控制器,分别相当于处理器的身体和大脑。
- 数据通路(datapath)负责完成算术运算。
- 控制器(control)负责指导数据通路、存储器和 I/O 设备按照程序的指令正确执行。
- 芯片中还有存储器芯片。内存(memory)是程序运行时的存储空间,它同时也用于保存程序运行时所使用的数据。内存由多片 DRAM 芯片组成,用来承载程序的指令和数据。与串行访问内存(如磁带)不同的是,无论数据存储在什么位置,DRAM 访问内存所需的时间基本相同。
- 在处理器内部使用的是另外一种存储器:高速缓存。高速缓存(cache memory)是一种小而快的存储器,一般作为 DRAM 的缓冲。高速缓存采用的是另一种存储技术,称为静态随机访问存储器 SRAM,其速度更快而且不那么密集,因此价格比 DRAM 更贵。
一旦关掉电源,所有数据就丢失了,因为计算机中的内存是易失性存储。与之不同的是,如果关掉 DVD 机的电源,所记录的内容将不会丢失,因为 DVD 采用的是非易失性存储。为了区分易失性存储与非易失性存储, 我们将前者称为主存储(main memory)或主要存储(primary memory),将后者称为辅助存储(secondary memory)。辅助存储形成了存储层次中更低的一层。
- DRAM 自 1975 年起在主存储中占主导地位,而磁盘在辅助存储中占主导地位的时间更早。
- 由于器件尺寸和前面所述的特点,非易失性半导体存储 —— 闪存(flash memory)在个人移动设备中替代了磁盘。除了非易失性外,闪存比 DRAM 慢,但却便宜很多。虽然每位的价格高于磁盘,但是闪存在体积、电容、可靠性和能耗方面都优于磁盘。因此闪存是个人移动设备中的标准辅助存储。
- 与硬盘和 DRAM 不同的是,闪存在写入 $100000 \sim 1000000$ 次后可能老化或损坏。因此,文件系统必须记录写操作的数目,而且具备类似 “移动常用的数据” 这种避免存储器损坏的策略。

Performance of the Computer
不同情境下的评价侧重不同。如果在两台不同的桌面计算机上运行同一个程序,那么可以说首先完成作业的那台计算机更快。如果运行的是一个数据中心,有好几台服务器供很多用户投放作业,那么应该说在一天之内完成作业最多的那台计算机更快。个人计算机用户会对降低响应时间(response time)感兴趣,而数据中心的管理者感兴趣的常常是提高吞吐率或带宽。简而言之,个人移动设备更关注响应时间,而服务器则更关注吞吐率。
- 响应时间(execution time)是指从开始一个任务到该任务完成的时间,又被称为执行时间。
- 吞吐率或者带宽(band-width)指的是单位时间内内完成的任务数。
- 在实际的计算机系统中,响应时间和吞吐率往往相互影响。
为了使性能最大化,我们希望任务的响应时间或执行时间最小化。对于某个计算机 $\text{X}$,我们可将其性能和执行时间的关系表达为:
这意味着如果有两台计算机 $\mathrm{X}$ 和 $\mathrm{Y},\ \mathrm{X}$ 比 $\mathrm{Y}$ 性能更好,则有
计算机经常被共享使用,一个处理器也可能同时运行多个程序。在这种情况下,系统可能更侧重于优化吞吐率,而不是致力于将单个程序的执行时间变得最短。因此,我们往往要把运行自己任务的时间与一般的运行时间区别开来。
- 我们使用 CPU 执行时间来进行区别,简称为 CPU 时间,只表示在 CPU 上花费的时间,而不包括等待 I/O 或运行其他程序的时间。(需要注意的是,用户所感受到的是程序的运行时间, 而不是 CPU 时间)
- CPU 时间还可进一步分为用于用户程序的时间和操作系统为用户程序执行相关任务所花去的 CPU 时间。前者称为用户 CPU 时间而后者称为系统 CPU 时间。要精确区分这两种 CPU 时间是困难的,因为通常难以分清哪些操作系统的活动是属于哪个用户程序的,而且不同操作系统的功能也千差万别。
- 为了一致,我们保持区分基于响应时间的性能和基于 CPU 执行时间的性能。我们使用术语系统性能 (system performance)表示空载系统的响应时间,并用术语 CPU 性能(CPU performance)表示用户 CPU 时间。
几乎所有计算机的构建都需要基于时钟,该时钟确定各类事件在硬件中何时发生。这些离散时间间隔被称为时钟周期数(clock cycle,或称滴答数、时钟谪答数、时钟数、周期数)。一个简单公式可以将最基本的指标与 CPU 时间联系起来:
由于时钟频率和时钟周期长度互为倒数,故另一种表达形式为
由于编译器明确生成了要执行的指令,且计算机必须通过执行指令来运行程序,因此执行时间必然依赖于程序中的指令数。一种考虑执行时间的方法是,执行时间等于执行的指令数乘以每条指令的平均时间。因此,一个程序需要的时钟周期数可写为:
指令平均时钟周期数(Clock cycle Per Instruction)表示执行每条指令所需的时钟周期平均数,缩写为 CPI。根据所完成任务的不同,不同的指令需要的时间可能不同,CPI 是程序的所有指令所用时钟周期的平均数。
最后,我们能构造出基本的性能公式:
平均 CPI 的计算公式如下:

- Instructions per Program(每个程序的指令数):表示在执行一个程序时所涉及的指令数量。
- Clock cycles per Instruction(每个指令的时钟周期数):表示执行每个指令所需的时钟周期数。不同的指令可能需要不同数量的时钟周期来执行。
- Seconds per Clock Cycle(每个时钟周期的秒数):表示每个时钟周期的时间长度。
将这三个因素相乘,就得到了总的 CPU 时间,即程序执行所需的时间。假设一个程序有 1000 条指令,每个指令平均需要 5 个时钟周期来执行,每个时钟周期的时间为 0.001 秒。那么,可以使用上述公式计算 CPU 时间:
计算结果为 5 秒每程序。
下表概括了不同的部分和影响 CPU 性能公式中的各种因素:
| 硬件或软件指标 | 影响什么 | 如何影响 |
|---|---|---|
| 算法 | 指令数,CPI | 算法决定源程序执行指令的数目,从而也决定了 CPU 执行指令的数目。算法也可能通过使用较快或较慢的指令影响 CPI。例 如,当算法使用更多的除法运算时,将会导致 CPI 增大 |
| 编程语言 | 指令数,CPI | 编程语言显然会影响指令数,因为编程语言中的语句必须翻 译为指令,从而决定了指令数。编程语言也可影响 CPI,例如, Java 语言充分支持数据抽象,因此将进行间接调用,需要使用 CPI 较高的指令 |
| 编译器 | 指令数,CPI | 因为编译器决定了源程序到计算机指令的翻译过程,所以编 译器的效率既影响指令数又影响 CPI。编译器的角色可能十分 复杂,并以多种方式影响 CPI |
| 指令系统 体系结构 |
指令数,时钟频率,CPI | 指令系统体系结构影响 CPU 性能的所有三个方面,因为它影 响完成某功能所需的指令数、每条指令的周期数以及处理器的 时钟频率 |
- 当今的计算机可以使用不同的时钟频率,所以我们需要对程序使用平均时钟频率。

RISC-V
Instruction Set is the repertoire of instructions of a computer. Different computers have different instruction sets, but with many aspects in common. In this note, we use RISC-V, which developed at UC Berkeley as open ISA.
RISC-V has a 32 × 64-bit register file, used for frequently accessed data.
- 64-bit data is called a “doubleword”. 32-bit data is called a “word”.
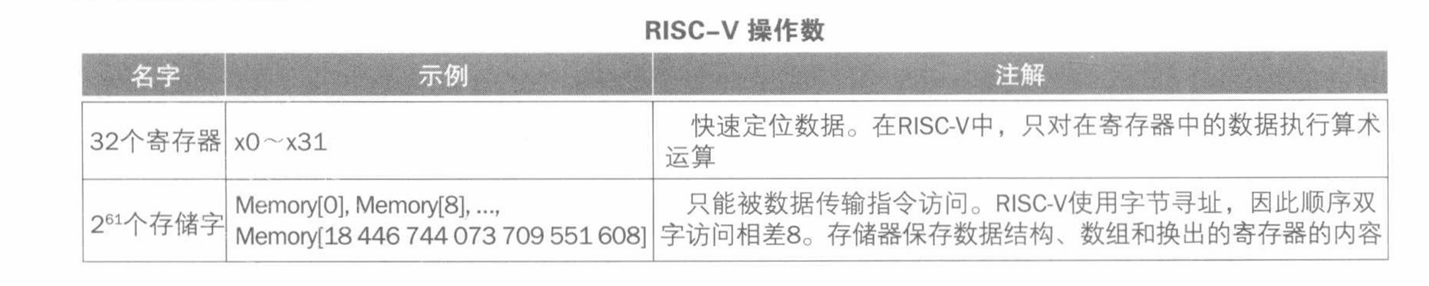
- $2^{63}$ 个字节。

Design Principle:
- 简单源于规整,Simplicity favours regularity. Regularity makes implementation simpler. Simplicity enables higher performance at lower cost.
- 越小越快,Smaller is faster.
- Good design demands good compromises. Different formats complicate decoding, but allow 32-bit instructions uniformly.
Basic Operations
Arithmetic Operands: add and subtract, with two sources and one destination.
- form:
add a, b, c // a = b + c - Arithmetic instructions use register operands.
Memory Operands: Load values from memory into registers and store result from register to memory.
- form:
ld x9, 64(x22), sd x9, 96(x22) A[12]=A[8] - Main memory used for composite data: Arrays, Structures, dynamic data.
- Registers are faster to access than memory. Operating on memory data requires loads and stores, hence compiler must use registers for variables as much as possible to optimize the efficiency.
- Memory is byte addressed: each address identifies an 8-bit byte.
- RISC-V is Little Endian: Least-significant byte at least address of a word.
0x14532DCB→xCBx2Dx53x14
- RISC-V does not require words to be aligned in memory.
- 在 x86 架构中,为了提高访问效率,要求内存中存储的 32 位或 64 位数据必须按 4 字节或 8 字节边界对齐,也就是字的起始地址必须是 4 或 8 的整数倍。但是在 RISC-V 中,并没有这种要求。一个32位的整数可以被存储在内存的任意地址,不需要是4字节对齐的。这样可以提高内存利用率,但是可能降低访问效率。

Immediate Operands: Constant data specified in an instruction, making the common case fast.
- form:
addi x22, x22, 4 - Immediate operand avoids a load instruction.
- 设置立即数操作数的原因是遵循 make the common case fast 这一设计原则。
- Register x0 里面保存着常量 0,用途很多,比如计算负数。
Representing Instructions
Instructions are encoded in binary, called machine code. RISC-V instructions are all encoded as 32-bit instruction words, embodying the principle of regularity.
R (Register) - Format Instrucion:


I (Immediate) - format Instructions:

12 位 immediate 字段为补码值,所以它可以表示从 $-2^{11}$ 到 $2^{11}-1$ 之间的整数。超过 32 个寄存器在这种格式下使用起来会很困难,因为 rd 和 rs1 字段都需要增添额外的一位,这导致一个字是不够的。
- 当 I 型格式用于加载指令时,immediate 字段表示单位为字节的偏移量,所以加载双字指令可以取相对于基址寄存器
rd中基地址偏移 2048 字节的任何双字。 - 这与计算 PC 相对地址的指令如
jalr等不同,后者的 immediate 字段是以指令字(32 位)为单位的。
S-format Instructions:

指令格式通过操作码字段中的值来区分:每个格式在第一个字段(opcode)中被分配了一组不同的操作码值,以便硬件知道如何处理指令的其余部分。

Logical Operations
Here is the table of instructions for bitwise manipulation:
- AND: Useful to mask bits in a word. Select some bits, clear others to 0.
- OR: Useful to include bits in a word. Set some bits to 1, leave others unchanged.
- XOR: 1→0 and 0→1.
- 为了保持三操作数格式,RISC-V 的设计者决定引入指令 XOR 来代替 NOT。因为异或是在两个操作数对应位相同时设 0,不同时设 1,所以 NOT 等价于异或
1111....1111。

这些移位指令使用 I 型格式。因为它不适用于对一个 64 位寄存器移动大于 63 位的操作,只有 I 型格式中 12 位的 immediate 字段中的低 6 位被实际使用。其余的 6 位被重新用作额外的操作码字段,,即 funct 6。
- 逻辑左移提供了另外一个好处:左移 $i$ 位相当于乘以 $2^i$, 就像是十进制数左移 $i$ 位相当于乘以 $10^i$ 一样。
- RISC-V 提供了第三种类型的移位指令 —— 算术右移
srai。这个变体与srli很相似,但它不是用零填充空出的左边的位,而是用原来的符号位来填充。它还提供了三个移位操作的变体:sll、srl和sra,他们从寄存器中取出移位的位数。
Conditional Operations and Loop
Conditional Operations: Branch to a labeled instruction if a condition is true; otherwise, continue sequentially.
beq rs1, rs2, L1 // if (rs1 == rs2) branch to instruction labeled L1bne rs1, rs2, L1 // if (rs1 != rs2) branch to instruction labeled L1blt (Signed comparison unsigned: bltu) rs1, rs2, L1 // if (rs1 < rs2) branch to instruction labeled L1bge (Signed comparison unsigned bgeu) rs1, rs2, L1 // if (rs1 >= rs2) branch to instruction labeled L1

- 一般来说,如果我们测试相反的条件来进行跳转,代码将更有效率。
Example C code:
1 | while (save[i] == k) i += 1; |
- i in
x22, k inx24, address of the array saved inx25.
1 | Loop: slli x10, x22, 3 // x10 = 8i |
大多数编程语言都包含 case 或 switch 语句,允许程序员根据某个值选择多个分支中的一个。实现 switch 的最简单方法是通过一系列的条件测试,将 switch 语句转换成 if-then-else 语句。
有时,另一种更有效的方法是编码形成指令序列的地址表,称为分支地址表或分支表,程序只需要索引到表中,然后跳转到合适的指令序列。因此,分支表只是一个双字数组,其中包含与代码中的标签对应的地址。该程序将分支表中的相应条目加载到寄存器中,然后需要使用寄存器中的地址进行跳转。
为了支持这种情况,RISC-V 这类指令系统包含一个间接跳转指令,该指令对寄存器中指定的地址执行无条件跳转。在 RISC-V 中,跳转 - 链接指令 jalr 用于此目的。
Procedure Calling
Basic Blocks: A basic block is a sequence of instructions with 1. no embedded branches (except at end) ; 2. No branch targets (except at beginning).
- A compiler identifies basic blocks for optimization.
- An advanced processor can accelerate execution of basic blocks.
过程(procedure)或函数是编程人员用于结构化编程的一种工具,两者均有助于提高程序的可理解性和代码的可重用性。过程允许程序员一次只专注于任务的一部分;参数可以传递数值并返回结果,因此用以充当过程和其余程序与数据之间的接口。
Procedure Calling:
- Place parameters in registers
x10tox17; 把参数放在过程可以访问到的位置; - Transfer control to procedure; 把控制转交给过程;
- Acquire storage for procedure; 获取过程所需的存储资源;
- Perform procedure’s operations; 执行任务;
- Place result in register for caller; 将结果值放在调用程序可以访问到的位置;
- Return to place of call (address in
x1). 将控制返回到初始点,因为过程可以从程序的多个点调用。
Procedure call:
- Use the operation:
jal x1, ProcedureLabel(jalmeans jump and link ). Address of following instruction put inx1, then jumps to target address.
Procedure return:
- Use the operation:
jalr x0, 0(x1). Likejal, but jumps to0+addressinx1. - Use
x0asrd(x0cannot be changed ). - Can also be used for computed jumps, like case/switch statements.
寄存器 jal 指令跳转到存储在寄存器 x1 中的地址。因此,调用程序或称为调用者(caller)将参数值放入 x10 ~ x17 中,并使用 jal 跳转到过程 X(有时被称为被调用者 callee)。被调用者执行计算,将结果放在相同的参数寄存器中, 并使用 jalr 将控制返还给调用者。
在存储程序概念中,需要一个寄存器来保存当前执行指令的地址。由于历史原因,这个寄存器总是被称为程序计数器,尽管其更合理的名称可能是指令地址寄存器。jal 指令实际上将 $\mathrm{PC}+4$ 保存在其指定寄存器 (通常为 $\times 1$ ) 中,以链接到后续指令的字节地址来设置过程返回。

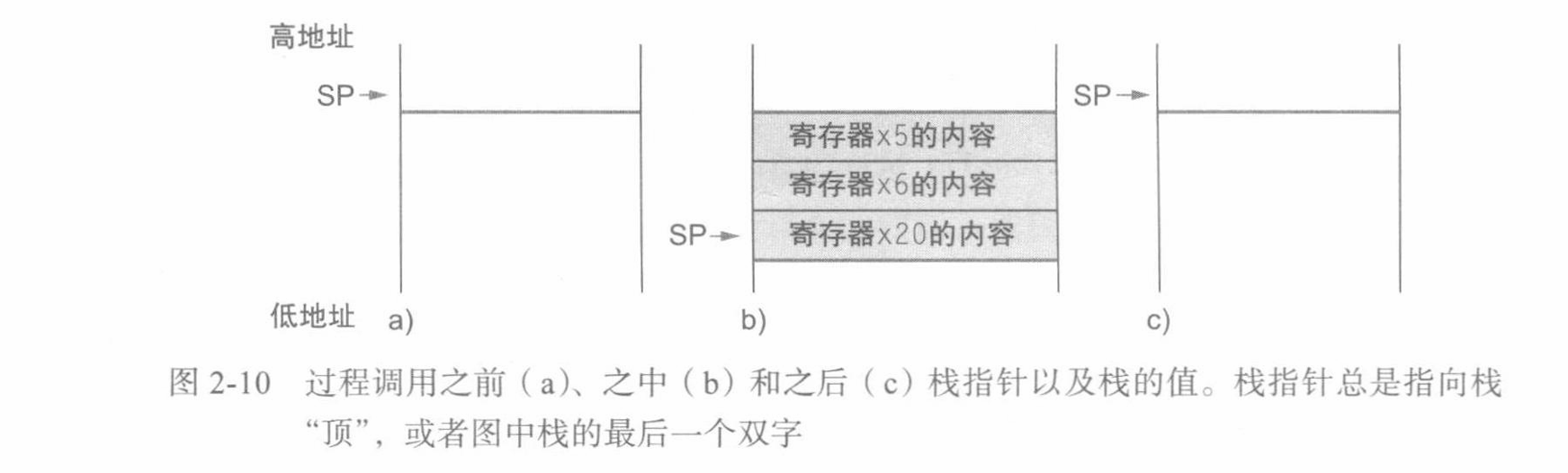
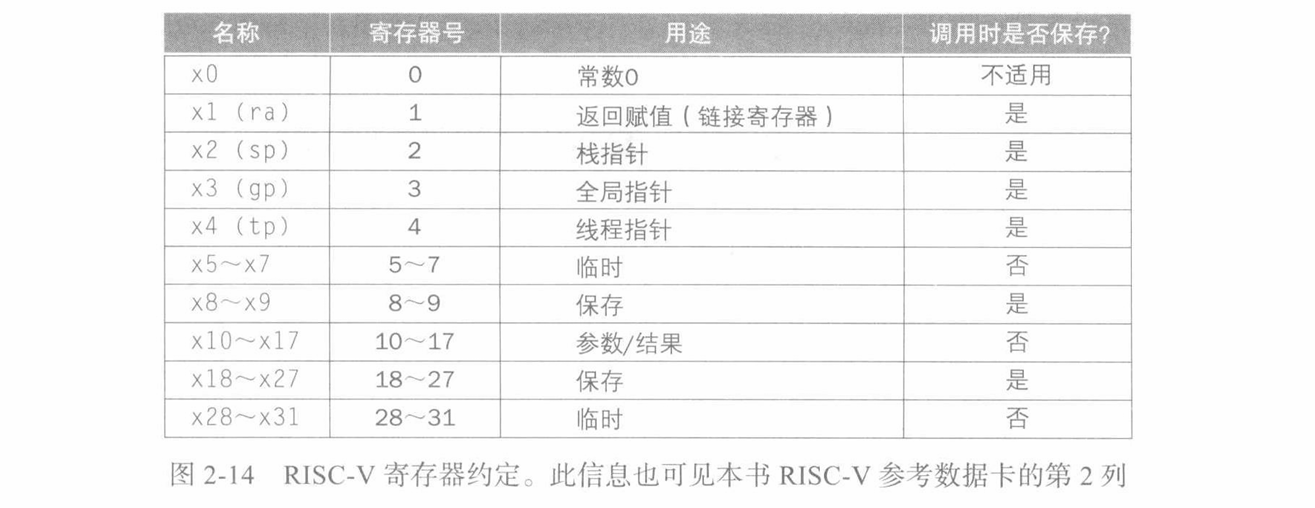
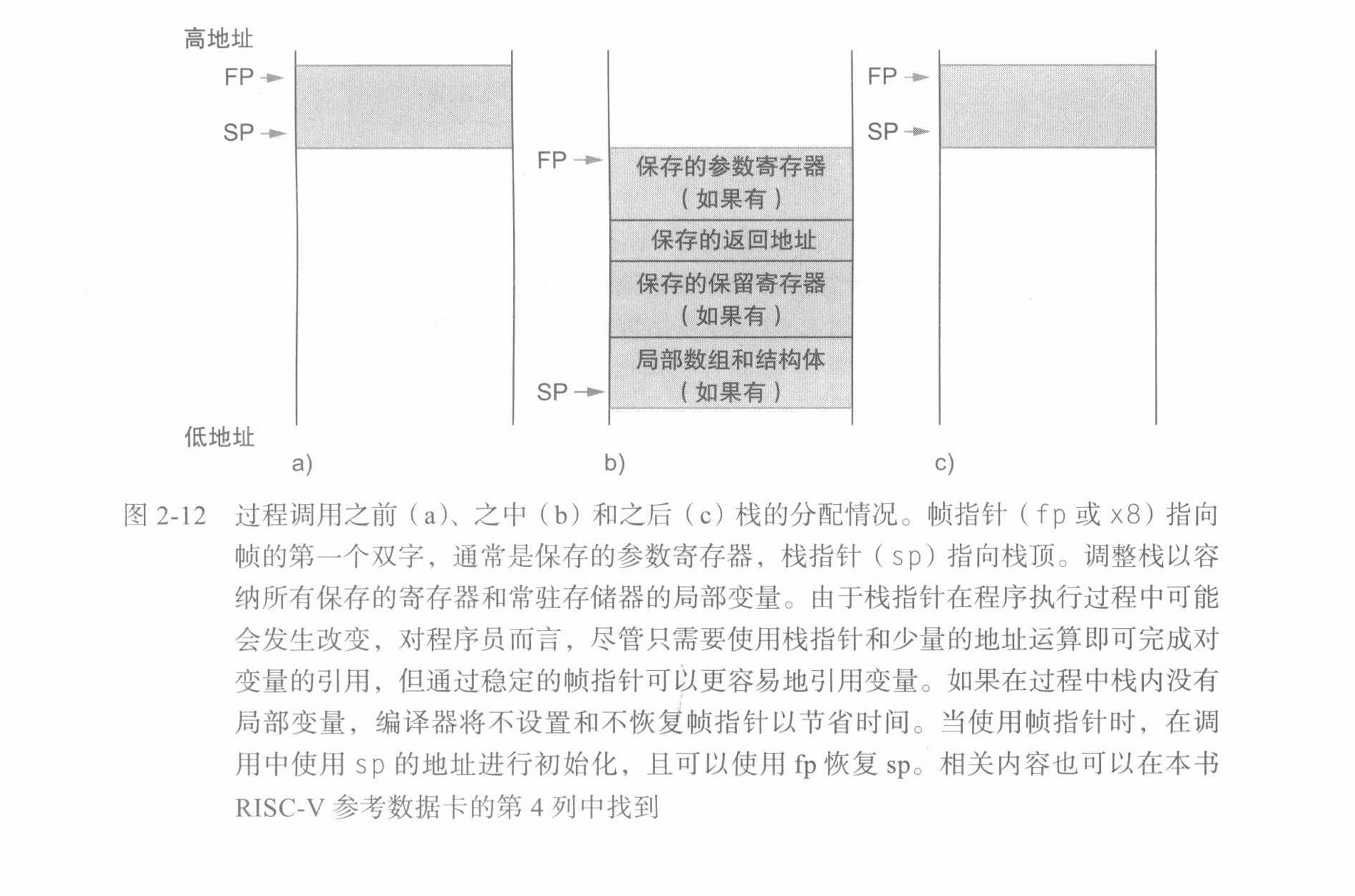
换出寄存器的理想数据结构是栈 —— 一种后进先出的队列。栈需要一个指向栈中最新分配地址的指针,以指示下一个过程应该放置换出寄存器的位置或寄存器旧值的存放位置。在 RISC-V 中,栈指针(stack pointer)是寄存器 x2,也称为 sp。栈指针按照每个被保存或恢复的寄存器按双字进行调整。
- 按照历史惯例,栈按照从高到低的地址顺序 “增长” 。这就意味着可以通过减栈指针将值压栈;通过增加栈指针缩小栈,从而弹出栈中的值。
Example C code:
1 | long long int leaf_example( |
Analysis and RISC-V Code
- Arguments
g, h, i, jinx10, x11, x12, x13. finx20and temporariesx5, x6. We need to savex5, x6, x20on stack.- Return register
x10.
1 | addi sp, sp, -24 |

x5–x7,x28–x31: temporary registers. Not preserved by the callee.x8–x9,x18–x27: saved registers. If used, the callee saves and restores them.x10-x17: Argument registers.
在 RISC-V 的调用约定中,具体的规定可能有所不同,因为 RISC-V 允许不同的调用约定。一般来说,调用者(caller)负责将参数传递给被调用者(callee),而被调用者负责保存和恢复调用前后需要保持不变的寄存器。
参数寄存器是x10到x17。这些寄存器一般来说是由调用者来设置的,而被调用者不需要保存它们,因为被调用者可以自由使用这些寄存器而无需担心破坏调用者的数据。
因此,一般情况下,x10到x17寄存器的值不需要由被调用者保存和恢复。被调用者主要关心的是保存和恢复那些被调用者可能会修改的寄存器,例如x8到x9和x18到x27。
不调用其他过程的过程被叫做叶子(leaf)过程。

Non-Leaf Procedures: Procedures that call other procedures. For nested call, caller needs to save its return address and any arguments and temporaries needed after the call on the stack, then restore from the stack after the call.
- 对于嵌套的过程调用,调用者函数在调用其他函数前,需要先将一些信息,如返回地址、参数、临时变量等数据保存到堆栈中。因为在调用后会从被调用的函数返回,此时需要依据堆栈中的数据恢复调用者函数的上下文环境。这样调用者函数才能接着正确执行, 而不会因为调用其他函数而丢失了自身的一些状态信息。

Example C code:
1 | long long int fact(long long int n) |
- Argument n in
x10and result inx10.
1 | addi sp, sp, -16 // Save return address and n on stack |
这些保存通常是 callee 的责任。
Stack and Heap
这个章节不是很重要,遂直接截图而不做摘抄。
栈也用于存储过程的局部变量,但这些变量不适用于寄存器,例如局部数组或结构体。栈中包含过程所保存的寄存器和局部变量的段称为 过程帧 或 活动记录。


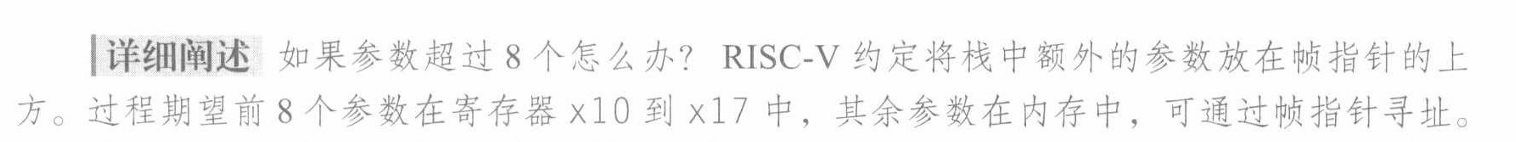


HCI
这个章节同样不是很重要。






Large Immediate Number
虽然常量通常很短并且适合 12 位字段,但有时它们也会更大。RISC-V 指令系统包括指令 load upper immediate (取立即数高位,lui)用于将 20 位常数加载到寄存器的第 31 位到第 12 位。将第 31 位的值复制填充到最左边 32 位,最右边的 12 位用 0 填充。例如,这条指令允许使用两条指令创建 32 位常量。lui 使用新的指令格式 U 型,因为其他格式不能支持如此大的常量。
- U 格式指令:
imm[31:12], rd, opcode


注意:
这段在原书中解释的是一坨。我们举个例子:例如,我们想生成一个 32 位的立即数 0xFEEDA987,我们需要先用 lui 指令把 0xFEEDB 加载到寄存器的高 20 位,低 20 位为 0。然后,用 addi 指令把 0x987 加到寄存器的值上,并把结果存入寄存器。
- 这是因为
0x987是一个负数,它在加法运算时会被符号拓展成0xFFFFF987,因此我们需要给 20 的立即数一个 +1 操作(FFFFF+1=00000)
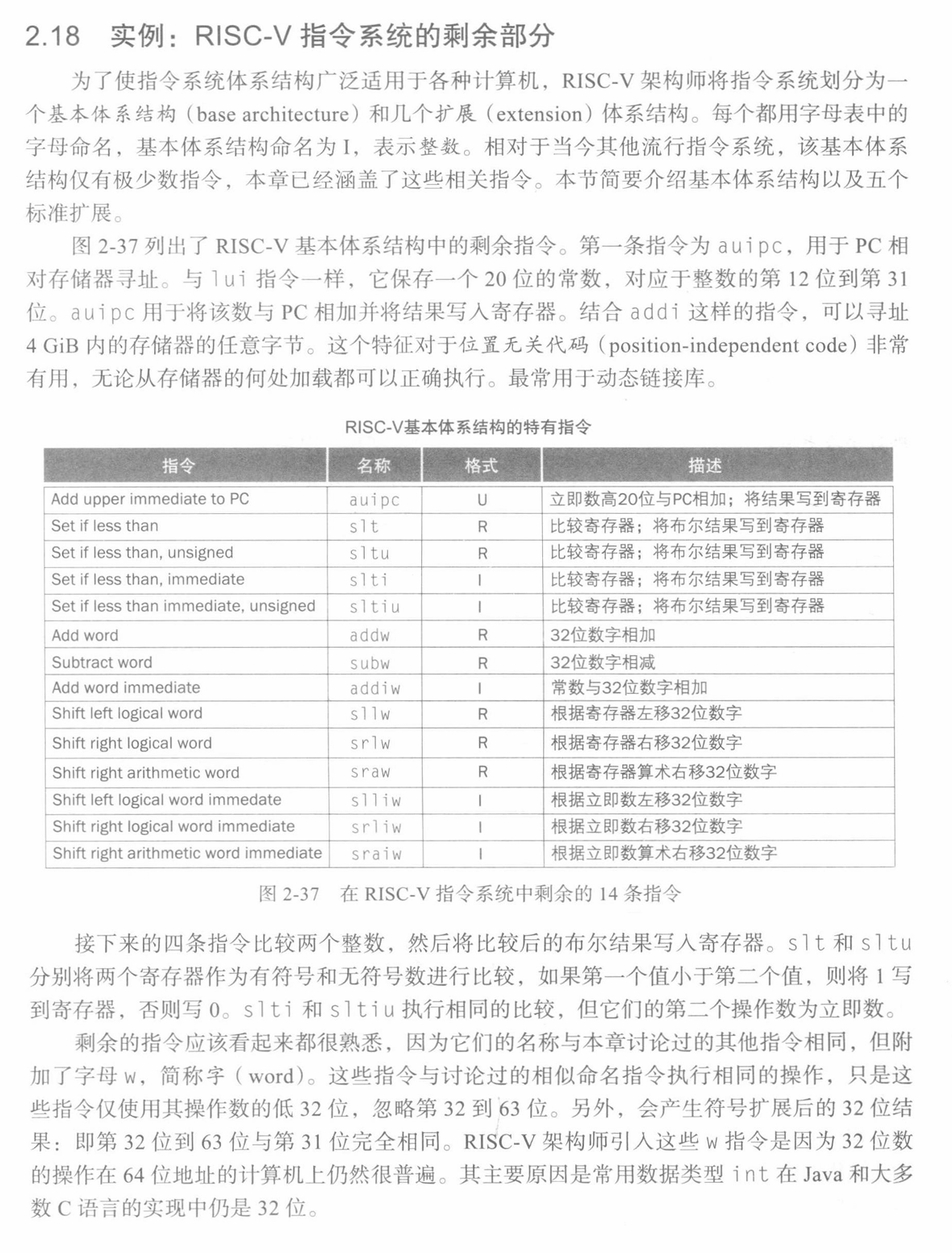
除此之外,RISC-V 还有 auipc 指令(Add Upper Immediate to PC),用于将一个无符号的立即数扩展到 32 位并与当前 PC(程序计数器)的上半部分相加,然后将结果存储到目标寄存器中。这主要用于生成全局地址,格式为:auipc rd, imm,过程为 rd = PC + sext(imm[31:12]),其中 sext 表示符号扩展。
例如,如果有以下的 RISC-V 汇编代码:auipc x1, 0x12345
这将把 0x12345 << 12 的值加到当前 PC 的上半部分,然后将结果存储到寄存器 x1 中。这个指令用于生成一个全局地址,通常在进行全局变量或程序中的全局跳转时使用。
需要注意的是,auipc 指令仅修改目标寄存器的上半部分,而不影响下半部分。通常,auipc 指令会与其他指令一起使用,例如 lui 指令,以生成完整的 32位地址。
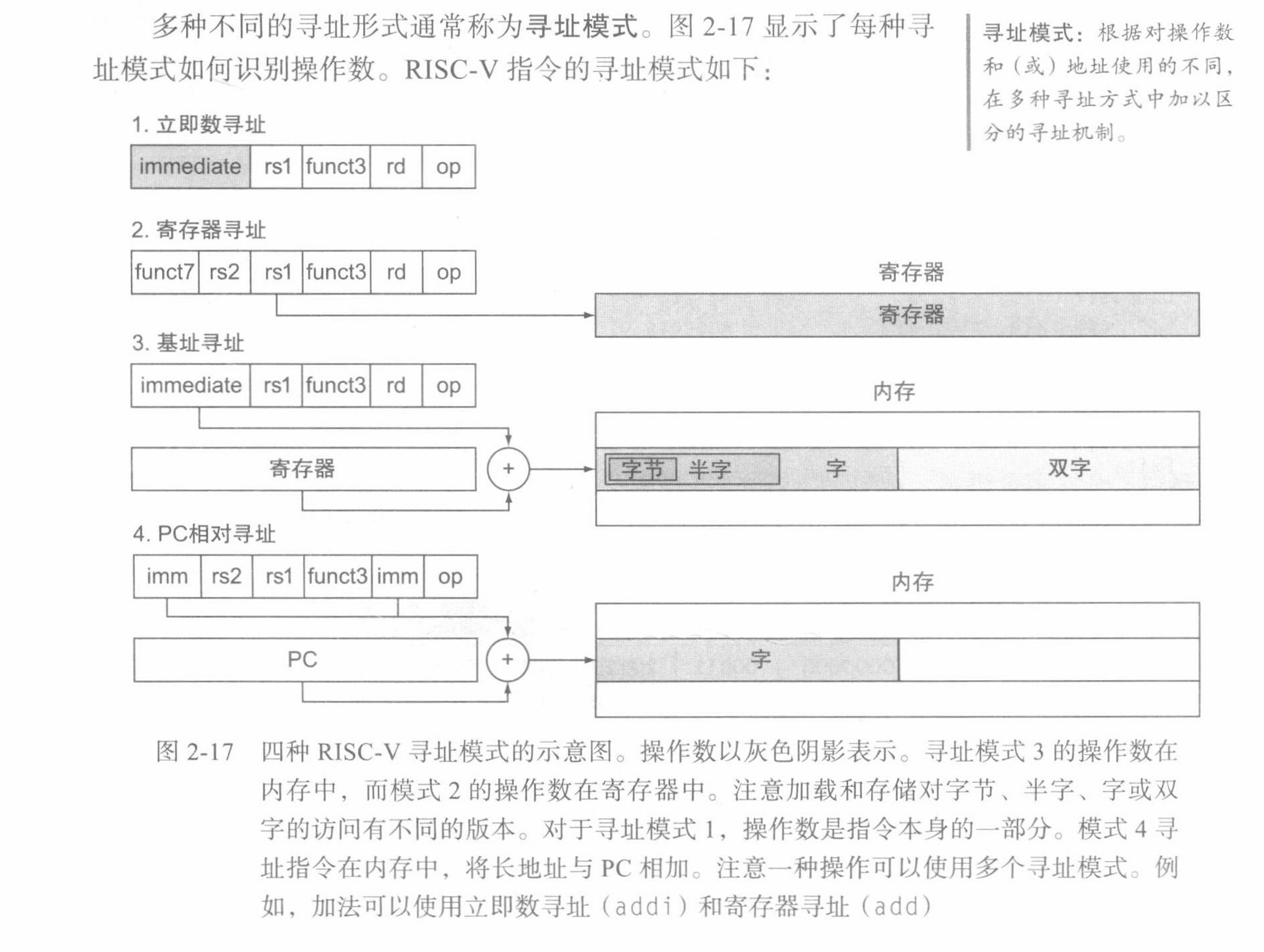
Addressing
RISC-V 分支指令使用称为 SB 型的 RISC-V 指令格式。这种格式可以表示从 -4096 到 4094 的分支地址,以 2 的倍数表示。由于最近的一些原因,它只能跳转到偶数地址。SB 型格式包括一个 7 位操作码、一个 3 位功能码、两个 5 位的寄存器操作数和一个 12 位地址立即数。该地址使用特殊的编码方式,简化了数据通路设计,但使组装变得复杂。bne x10, x11, 2000 这条指令可以组装为这种形式:

无条件跳转 — 链接指令 jal 是唯一使用 UJ 型格式的指令。该指令由一个 7 位操作码、一个 5 位目标寄存器操作数(rd)和一个 20 位地址立即数组成。链接地址,即 jal 之后的指令的地址,被写入 rd 中。与 SB 型格式一样,UJ 型格式的地址操作数使用特殊的立即数编码方式,它不能编码奇数地址。所以 jal x0, 2000 被组装为这种格式:

如果程序的地址必须适合这个 20 位字段,对于今天的需求来说太小,另一种方法是指定一个与分支地址偏移量相加的寄存器,以便分支指令可以按如下来计算:
由于 PC 包含当前指令的地址,如果我们使用该 PC 作为寄存器,可以在距离当前指令的 $\pm\ 2^{10}$ 个字的地方分支,或者跳转到距离当前指令 $\pm\ 2^{18}$ 个字的地方。几乎所有循环和 if 语句都小于这个限制,因此 PC 是理想的选择。这种形式的寻址方式成为 PC 相对寻址。
与最新的计算机一样,RISC-V 对条件分支和无条件跳转使用 PC 相对寻址,因为这些指令的目标地址可能距离分支很近。另一方面,过程调用可能需要转移超过 $2^{18}$ 个字的距离,因为不能保证被调用者接近调用者。因此。RISC-V 允许使用双指令序列来非常长距离地跳转到任何 32 位地址。
由于 RISC-V 指令长度为 4 个字节,因此 RISC-V 分支指令可以设计为通过让 PC 相对偏移表示分支和目标指令之间的字数而不是字节数,以便扩展其范围。但是,RISC-V 架构师也希望支持只有 2 个字节长的指令,因此 PC 相对偏移表示分支和目标指令之间的半字数。因此,jal 指令中的 20 位地址字段可以编码为距当前 $\mathrm{PC} \pm 2^{19}$ 个半字或 $\pm 1 \mathrm{MiB}$ 的距离。类似地,条件分支指令中的 12 位立即数字段也是半字地址,这意味着它表示 13 位的字节地址。

immediate的单位是 字节。但是,由于指令对齐和压缩指令的需要,immediate在计算目标地址时会被乘以2(即左移一位),使得偏移量以 2 字节(halfword) 为单位。这样,无论是标准的32位指令,还是16位的压缩指令,都可以正确地计算出目标地址。
Synchronization
非重点章节。这部分应该是操作系统课上着重学的。


Translation and Startup
非重点章节。
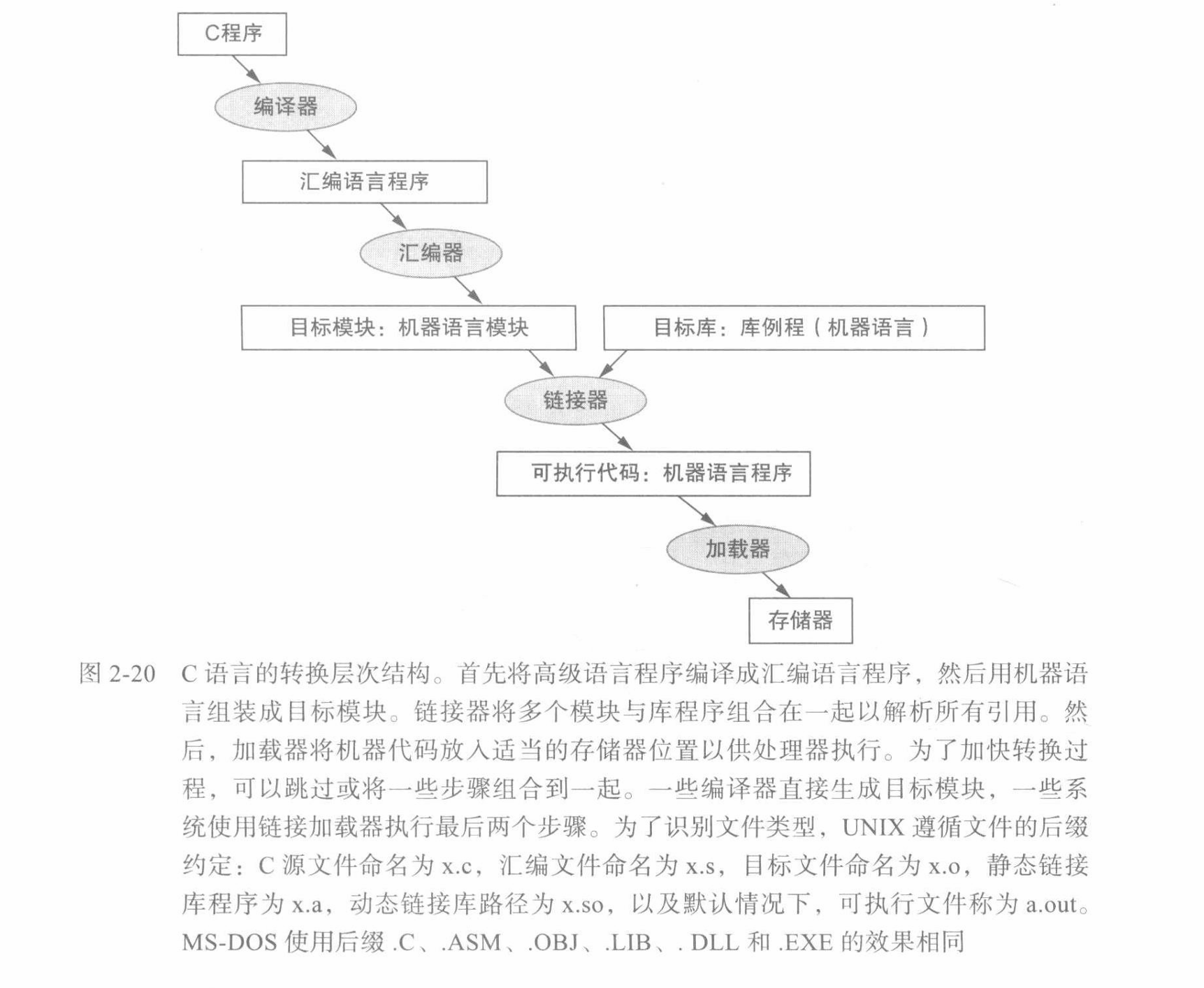
- 编译器将 C 程序转换为机器能理解的符号形式 —— 汇编语言程序。高级语言程序比汇编语言使用更少的代码行,因此程序员的工作效率更高。
- 汇编器从汇编语言程序转化为目标机器语言模块。
- 链接器将目标机器语言模块和静态库文件链接在一起,产生机器语言程序(可执行程序)。
- 加载器将可执行程序加载到存储器的内存中。